Mission defines strategy, and strategy defines structure
How our five phase pipeline revealed a bigger image on its own, and what that teaches us about context engineering across agent boundaries
Introduction
We didn’t plan it this way at the beginnig. When we first designed our failure analysis pipeline, we were solving problems one phase at a time: cluster the logs, triage the failures, validate the results, render the reports. Each phase had its own agent, its own prompt, its own tools. It wasn’t until we stepped back and looked at the whole system that we realized what we’d actually built: a ReAct system operating at the macro level, where each agent is one step in a much larger Thought-Action-Observation cycle.
It is not a loop in the strict sense. The pipeline doesn’t iterate back to an earlier phase. It runs forward, phase by phase, each one feeding the next. But the structure maps directly onto the ReAct pattern: reason, act, observe.
The ReAct Loop
ReAct (Reason + Act) is a prompt pattern where LLM agents alternate between Thought, Action, and Observation steps to solve tasks using tools. Some people call it the TAO cycle: Thought, Action, Observation. Programmers sometimes refer to it as “a big while loop.”
Putting that into pseudocode it works something like this.
context = system_prompt + user_question
while not done:
output = llm(context)
thought, action = parse(output)
if action == "finish":
return action.answer
observation = execute_tool(action)
context += f"\nThought: {thought}\nAction: {action}\nObservation: {observation}"
The loop continues until the model decides it has enough information to produce a final answer, or until you hit a step cap to prevent runaway execution and token wastage.
Each turn, the model reasons about what it knows (Thought), decides what to do next (Action), and receives new information (Observation).
After this, yet another shift emerged in building agents, where developers stepped away from the prompt engineering, which dominated AI community since 2022-2023. The new shift started somewhere mid-2025, and community called it the context engineering. This helped developers not depend on maintaining the entire context state including system instructions, memory, RAG pipelines, tool outputs and conversation history.
A minimal example
[System Prompt]
You are a ReAct agent.
Available tools: search, calculator.
Format: Thought: ... / Action: tool[input] / Observation: ...
Reply with "Final Answer: ..." when done.
[User]
What is the population of Amsterdam times 2?
[LLM turn 1]
Thought: I need to find Amsterdam's current population.
Action: search["Amsterdam population 2025"]
[Orchestrator executes search → returns "~950,000"]
[LLM turn 2] ← scratchpad now includes previous Thought+Action+Observation
Observation: ~950,000
Thought: Now I multiply 950,000 × 2.
Action: calculator["950000 * 2"]
[Orchestrator executes calculator → returns 1,900,000]
[LLM turn 3]
Observation: 1,900,000
Thought: I have the answer.
Final Answer: The population of Amsterdam (~950,000) times 2 is 1,900,000.The Harness and Scaffolding
Finally, somewhere in late 2025 and early 2026 we got term harness. The harness is short for “everything in an LLM AI agent except the model itself”.
The formula being: Agent = Model + Harness. It is the orchestration code that wraps around an LLM and turns it into a functioning agent. It handles prompt assembly, tool execution, output parsing, and context management. Each layer in harness is curated, each step should be delivered to the agent gently. Each layer competes for the model’s attention. The harness decides what goes in, what gets summarized, and what gets dropped.
The model itself only sees text and produces text; everything else is scaffolding around it. If you want to read more details regarding this, please visit this blog post [2]. The author also points out that the main culprit for agents failing is context engineering.
Why? Because the agents fail silently as the context degrades without any visible error, the model keeps responding… Just worse.
Context Engineering
Anthropic frames the goal of context engineering as: “Find the smallest possible set of high-signal tokens that maximize the likelihood of the desired outcome” [3]. This matters because models struggle with large contexts. Maybe for some familiar “lost in the middle” problem, where models recall information from the beginning and end of their context window better than from the middle, has been shown in multiple papers [1]. With the introduction of the harness we are actively shaping what the model can reason about.
Liu et al. [1] tested this directly. They buried a relevant document at different positions inside a long context and measured retrieval accuracy. The result is a U-shaped curve: models recall what’s at the beginning and end of the window, but performance drops sharply for anything in the middle. Sure, they did it on GPT-3.5-turbo with 20 documents, but all the other models are trained on the same principle. The results show that accuracy fell from 75% (first position) to 53% (middle positions), barely above the closed-book baseline of 56%. The model essentially forgot the middle of its own input.
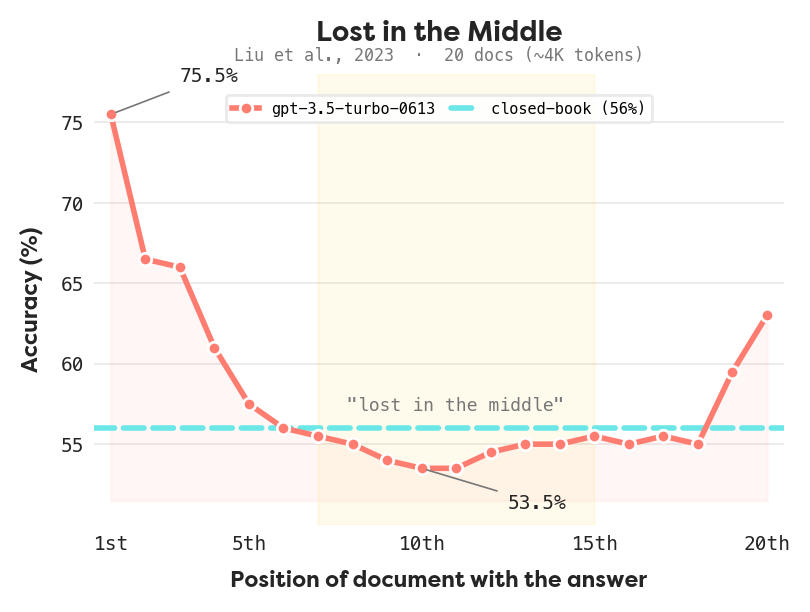
This is why context engineering matters. A naive approach, dump everything into the prompt, loses information where it counts most. The harness has to be deliberate about what goes where. Even LLMs have issue with attention, not just humans.
Each layer in harness is curated, each step should be selective and detailed, but not too detailed. Each layer competes for the model’s attention. The harness decides what goes in, what gets summarized, and what gets dropped. The model doesn’t make agents reliable. The structure around it does.
A typical harness assembles context in layers:
Scaffolding and guardrails are the temporary infrastructure that lets workers build a structure they couldn’t reach otherwise.
It doesn’t do the construction, but without it, the building doesn’t get finished. And when the scaffolding comes down, the building is complete. As models improve, harness complexity should decrease. The multi-step tool chains, careful context windowing, and output parsers that are necessary today may become unnecessary as models get better at managing their own reasoning and tool use.
Macro ReAct
Inside the loop: the micro steps
- Prompt assembly: the harness constructs the full context, including system prompt, tool definitions, conversation history, and the current observation
- LLM inference: the model returns text, a tool call request, or both
- Output classification: if no tool calls, the loop ends and the final answer is returned. If a tool call is present, proceed to execution
- Tool execution: the harness runs the requested tool and captures the result
- Result packaging: the tool output is formatted into an Observation the model can parse
- Context update: the new Thought + Action + Observation triple is appended to the conversation history
- Loop: return to step 1 with the updated context
Tip: Cap the maximum number of steps to prevent runaway execution. A model that keeps calling tools without converging on an answer is either confused or stuck, and the harness should bail out.

The macro overview: When Agents Become Steps
In our pipeline, we have five phases:
- Preprocessing: cluster logs by fingerprint, compute statistics, identify outliers and representatives.
- Triage (LLM calls): checks each entity for anomalies.
- Investigator (LLM): collects evidence from the results through independent investigation. It builds context for the downstream agents.
- Verdict (LLM): parallel entity verdicts, merging the incidents merging, and judge panel validation
- Reporting (LLM): per-incident reports generated by a coordinator with six specialized sub-agents
Some of these agents work linearly to produce results. Others have their own internal ReAct loop. The Verdict agent, for instance, has tools to list, compare, and merge anomalies. At the micro level, each is a standard ReAct agent doing its Thought-Action-Observation cycle.
But zoom out. The pipeline itself follows the same pattern:
- Prompt/Context Engineering corresponds to Preprocessing which analyzes raw data and identifies structural patterns. This is our macro prompt, which we will inject in downstream agents.
- Thought: The first agent in the pipeline, Triage, does the Thinking: classifying entities for anomalies or none thereof.
- Action + Observation: The Investigator is the agent which takes all the evidence, and has full knowledge on all the states and results of previous agents.
- Thought: One of the final agents, Verdict takes all the evidence accumulated so far (triage labels, investigator evidence, raw artifacts) and synthesizes it into judgement is something anomaly or not.
- Action: Reporting takes the validated incidents and produces the output.

The only agent with a dedicated observation phase is the Investigator but other aspect of this layer is the data itself. The structured JSON artifacts, the labels, the assessments, those are the observations. They’re the connective layer between agents, which is why we represent them with a dashed line in the diagram. The information flow is bigger picture of the observation. Each agent has tools which are able to access this information.
We designed each phase to solve its specific problem well. The macro pattern emerged naturally because ReAct isn’t just a design technique. It’s how any system works through a complex problem: reason about what you know, act to learn more, observe the results.
Design lessons
Building this pipeline taught us a few things about multi-agent system design:
Each agent should be a clean step. If an agent is trying to both reason and act in the pipeline-level sense (triaging and validating its own results), you’ve collapsed two macro steps into one. Split them.
Observations should be structured. The output of each phase needs to be legible to the next phase. Just like tool results in a micro loop need formatting for the model, inter-agent communication needs clear schemas.
Context engineering applies at every scale. The “lost in the middle” problem doesn’t just affect individual agents. It affects what artifacts you pass between phases. Our Verdict agent receives exactly curated number of artifacts per entity, not an entire dump. That curation is macro-level context engineering.
The step cap applies too. If your pipeline keeps looping between phases without converging, something is wrong. Build in circuit breakers at the macro level, just as you would at the micro level.
The ReAct loop is fractal. It works at every scale, from a single tool call inside one agent to the full orchestration of a multi-phase pipeline. We didn’t set out to build a macro ReAct loop. We just built good agents, and the pattern was already there.
Conclusion
At moyai, we work on tool which monitors you observability. We’re trying to bridge the gap between having logs and actually understanding what went wrong, giving you the Agent Reliability.
While solving this puzzle, and while making our agents more reliable, we started seeing patterns which are emerging, and this is one of the most satisfying parts of building this system, where you can retrospect yourself and then the design reveals the bigger meaning to you. It’s only when you step back to look from afar. The initial idea gets you moving, the actual steps and pieces give it the shape and meaning.

References
[1] N. F. Liu, K. Lin, J. Hewitt, A. Paranjape, M. Bevilacqua, F. Petroni, and P. Liang, “Lost in the middle: How language models use long contexts,” Trans. Assoc. Comput. Linguist., vol. 12, pp. 157–173, 2024. [Online]. Available: https://arxiv.org/abs/2307.03172
[2] A. Pachaar, “Context engineering for AI agents,” 2025. [Online]. Available: https://x.com/akshay_pachaar/status/2041146899319971922
[3] Anthropic, “Effective context engineering for AI agents,” 2025. [Online]. Available: https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
Wrap-up
AI agents can look fine in demos and still fail in production. Moyai helps teams catch reliability issues early with clustering, evaluation, and actionable alerts.
If that sounds like the kind of tooling you want to use — try Moyai or join us on Discord .